

Personal Gradient Ascent: How To Think Like A Machine
In 1943, the first artificial neural networks were inspired by our biological brains. We've learned a lot from ourselves. But maybe it's time to learn to think like a machine.

“A foolish consistency is the hobgoblin of little minds, adored by little statesmen and philosophers and divines.” — Ralph Waldo Emerson
I vividly remember the final days of my high school baseball career.
I felt like I was on top of the world.
After a breakout season, I'd just pitched the game of my life to propel us to the CIF Southern Section championship game.
I was wearing the logo of the D1 college team I had just committed to with pride.
By advancing to the collegiate level, I knew I'd made it to the last step before I'd be living my life-long dream of playing baseball professionally.
Every ounce of momentum was on my side, and I was ready to push forward into the next chapter of my life.
But when I got to my college campus, I got stopped dead in my tracks.
I suffered years of mediocre progress.
I began to struggle with elbow discomfort during the earliest days on my new team.
An MRI revealed I had torn my Ulnar Collateral Ligament (a ligament in my elbow).
I was forced to undergo Tommy John surgery (a full-on UCL reconstruction) leaving me unable to pitch for what I expected to be 12-14 months.
I ended up spending over two full years in rehab — only to emerge as a shadow of my former self.
After three and a half years of being dragged down by injuries, I decided I needed to move on.
I hung up my cleats without ever pitching a single inning for the team.
I could hardly keep my voice together when it came time to tell my friends, family, and coaches, who had supported me the whole way, about my decision.
I had to come to terms with the fact that my dream of playing in the big leagues would never come true.
There was one question that nagged at me:
"How could I have let this happen?"
The question festered in my mind, damaging my dignity and sense of self-worth.
Despite this, I pushed myself toward creating a new future outside of baseball.
I applied myself to academics with a fervor I never had before — I earned 22 A grades in a row to conclude my education.
During my master's program, I learned about subjects like statistics, programming, and machine learning.
I found the technical intricacies fascinating, but the underlying conceptual frameworks far more valuable.
The principles I learned influenced the very core of my philosophy on how to approach life.
But the importance of one concept completely overshadowed the rest:
Neural networks.
After studying how machines learn and improve over time, I noticed that a similar approach might be beneficial to my own self-improvement.
Since adopting this way of thinking, I can confirm this to be 100% true — it's driven me to new heights in every facet of my life.
The principles of building neural networks taught me:
how to learn from my mistakes
persistence
how to pace myself
iteration
It's also exposed flaws in the way I had tried to progress toward my goals in the past.
As a result, I finally have the answer to the burning question that had plagued my mind for over two years:
I failed because I stuck to approaches that weren’t working.
At the end of the day, my inputs hadn’t resulted in the outputs I had expected.
And I didn't have the awareness to change it until it was too late.
The hard work I put in to get back on the field was always diluted by other destructive behaviors.
For every step I took in the right direction:
physical therapy
weight training
conditioning
There were always counterproductive things to offset them:
alcohol & junk food
voluntary sleep deprivation
video games, binge scrolling on social media, partying
I was told I needed to be patient for good things to come.
But the premature end to my baseball career came from the opposite: a failure to change course and invest more of my time into the things that drove results.
Now that my story is out of the way — here are the lessons that neural networks taught me about self-improvement:
The Human Brain -> Artificial Neural Networks
The first artificial neural networks (ANNs) were inspired by the biological neurons found in our brains:
Sonar was first inspired by bat echolocation
Velcro was first inspired by plant burrs that attach to animal fur
Submarines were first inspired by the dimensions of fish
Planes were first inspired by the flight of birds
Over the course of their development, these technologies gradually evolved from nature-based conceptual designs.
For example, submarines don’t have moving fins or tails — they have propellers.
In the same way, modern neural networks have deviated from their original biological inspiration, but they still loosely maintain similarities to the neurons in our brains.
Here's how the neurons in your brain compare to one of the simplest neural network architectures: the perceptron.
Biological Neurons
Here’s an illustration of a single neuron cell:
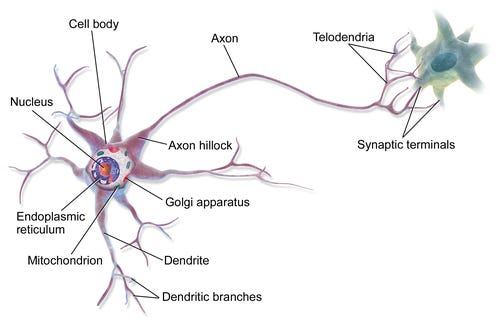
Dendrites - receives electrochemical signals from other neurons (inputs)
Synapses - the strength of each signal is modulated by synapses, which determine the importance of each input
Cell Body - process signals and integrates them together to determine overall level of activation
Thresholding Mechanism - if the level of activation exceeds a specific threshold, the neuron generates a spike in electrical activity
Axon - relays the electrical spike signal to other neurons (output)
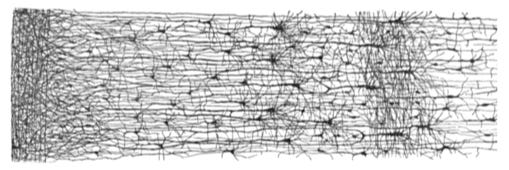
While the the above image might illustrate the anatomy of just one neuron, the total number of neurons in our brains is far from just one — it's been estimated to be around 86 billion!
The highly complex logic our brains are capable of is a result of these individual neurons’ ability to work together.
Here’s a drawing showing what numerous neurons look like strung together by their dendrites and axons:
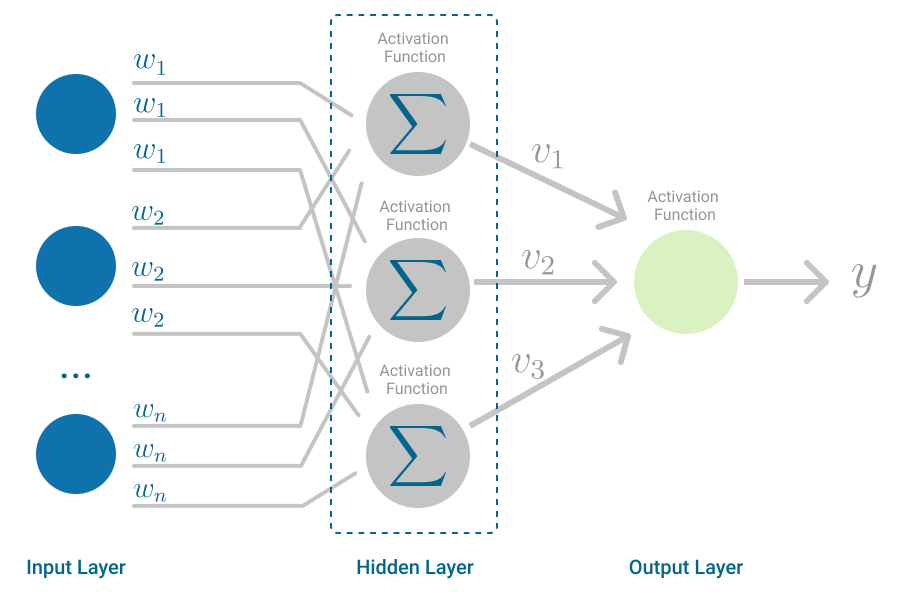
Perceptron (Artificial Neuron)
You’ll notice that the perceptron is extremely similar in structure to the biological neurons they’re modeled after:
 in Neural Networks | by Rukshan Pramoditha | Towards Data Science")
Inputs - a perceptron receives multiple inputs (x1, x2, …, xn), which represent the data being fed into the model.
Weights - each input to the perceptron is multiplied by a corresponding weight (w1, w2, …, wn), determining the importance of each input.
Summation - the perceptron sums the weighted inputs to produce a single value (Σ(wi * xi)), representing the combined influence of all inputs.
Activation Function - the perceptron applies an activation function to the summed input, determining whether or not it exceeds a certain threshold.
Output - if the activation function’s condition is met, the perceptron produces an output, often binary (0 or 1), indicating the perceptron’s decision or classification.
Just like the neurons in our brains, perceptrons can be chained together to create models that are capable of much more complex logic.
Here’s a visual displaying what is commonly called a multilayer perceptron (MLP):
Alright, now that you understand the basic structure of neurons and perceptrons, let’s ask two critical questions:
How do artificial neural networks actually learn to become just as good, if not better than humans at certain tasks?
And how can you optimize your own self-improvement by studying the neural network models we’ve created?
How Neural Networks Learn
If you have data to train your neural network on, you can create a model with shocking levels of intelligence within the span of a couple minutes (or even seconds).
Here's a brief introduction into the amazingly complex things you can train neural networks to do:
Email Spam Detection (Is an email spam or not?)
Object Detection (Does an image contain a human, a cat, or a dog?)
Social Media Sentiment Analysis (What do the masses think on a certain topic?)
Activity Recognition (Are you walking, running, lifting weights, or sitting right now?)
But how can this process be so efficient?
How is it possible that the model can learn such complex concepts so quickly?
An understanding of this process serves as the philosophy that will enable you to reach the pinnacle of any realm of human endeavor.
The entire process is systematized in an optimization algorithm — gradient descent.

The goal of gradient descent is to minimize a specific value.
In this case, we want to minimize the error (cost on the chart above) that our neural network suffers when making its predictions.
The error is the difference between the network’s predictions and the real value.
For example, assume you’ve trained a model to predict the price of house based on data you’ve collected.
If for a given set of inputs, your model predicts a price of $500,000 when the real price of the house is $1.4 million, you should probably go back to the drawing board.
Given enough quality data, a neural network can learn just about anything.
Better yet, leveraging the blazing speed of computers, artificial neural networks can perform this task at a breakneck pace.
So how is it done?
Recall that each input in our perceptron has a weight (importance) associated with it. First, we initialize a new neural network with random weights, feed it our data as inputs, and allow it produce an output.
Next, we calculate the overall amount of error by comparing the network’s output to the actual value it should have predicted.
Now, we need to figure out how much each weight contributed to the overall error.
To do this, we use a technique called backpropogation to compute the gradient for each weight.
Once we obtain each gradient, we can determine which direction we should adjust each weight to lower the error — we call this gradient descent.
We now adjust our weights by small or smaller amounts in the opposite direction of the gradient depending on how fast we would like our model to learn (learning rate).
Lastly, we feed our data as inputs yet again, and repeat the process above until the weights are set at values that accurately convert our inputs into the desired outputs. This is how neural networks “learn“ through training.
I know — it’s a lot.
I’ll spare you from the calculus involved, but if you’re curious to learn more, I won’t stop you.
But a surface level understanding of this process is all you need.
Now, I’m going to do two things:
Flip what you’ve learned on it’s head — we’re going to talk about gradient ASCENT (not descent)
Equip you with this framework to supercharge your self-improvement
The combination of the two points above = Personal Gradient Ascent.
Personal Gradient Ascent
First, let’s invert gradient descent.
Instead of optimizing for the lowest value we possibly can, we’re now optimizing for the highest value possible.
When applied to your personal life, the question is this:
How can you create a model that outputs the pinnacle version of you?
First, you need goals — this usually isn’t the hard part since everyone has them.
Next, you need to figure out what the most important factors are that will move you toward your goals.
Here’s how you can copy the neural network framework to do this:
Start tracking data on various metrics over time (create a dataset)
Calculate the degree each input contributed to your success (find what works for you)
Adjust each weight accordingly (double-down on what’s working, cut out the things that aren’t)
Take my fitness journey for example:
Thanks to my Whoop fitness tracker, I’m able to track dozens of metrics related to my health over time.
Tracking this data led me straight to the activity that has damaged my health the most:
I’ve suffered an average of 24% decline in my next-day recovery after my nights out drinking.
On top of that, I’m 11% worse than the average person’s next-day recovery.
Here’s a screenshot so you know I’m not just making it up:
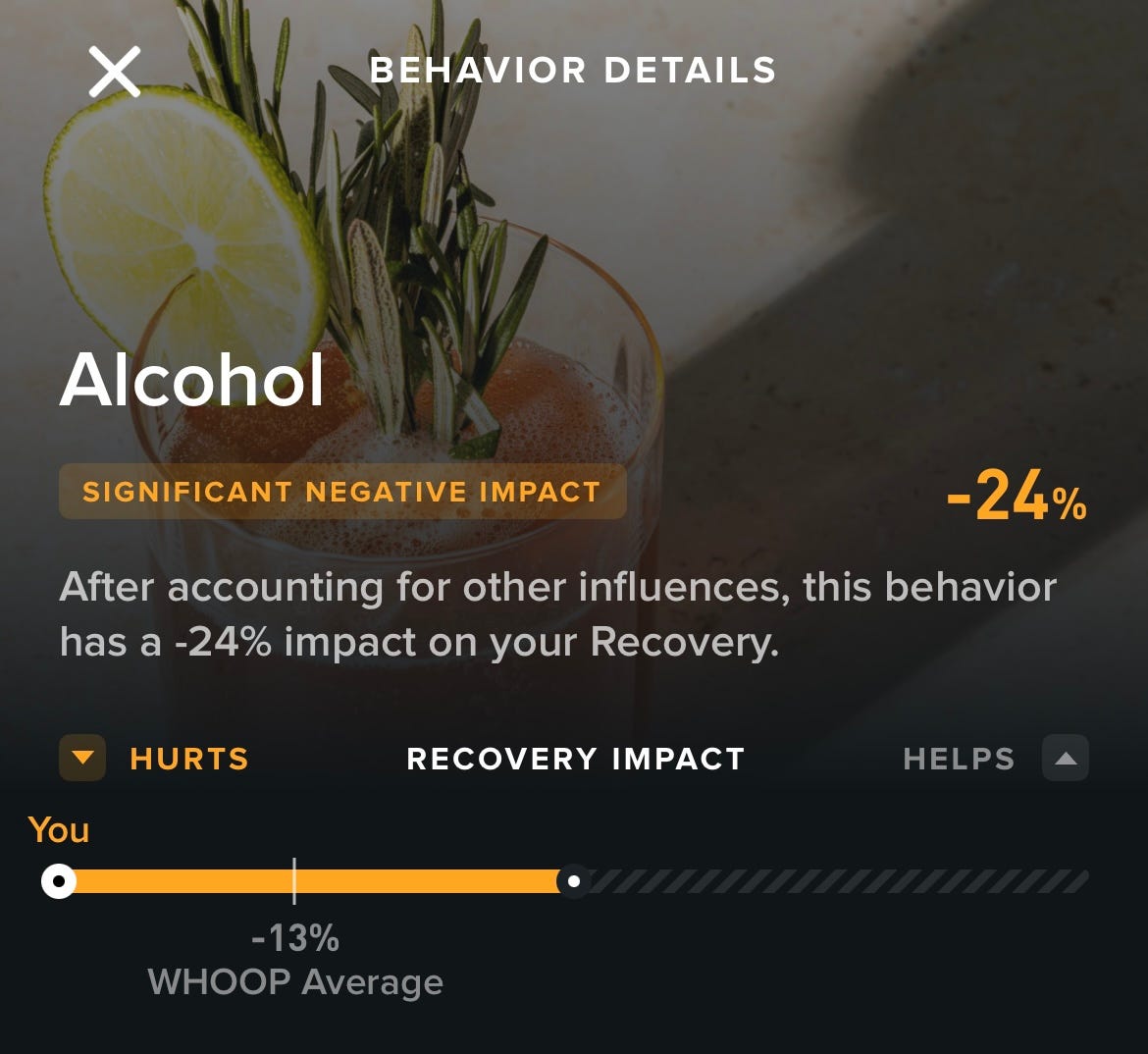
Thanks to the data, I can clearly see that drinking alcohol has a strong negative correlation to my health.
So what should I do in response?
Well, what would a neural network do?
It would increase weight on alcohol consumption (the network will place more importance on this variable.)
On the mornings following alcohol consumption, the model would predict lower recovery scores.
For a person who is looking to optimize their overall health, the evidence is clear:
Alcohol consumption isn’t a good thing.
Through research and experimentation, I’ve also come across metrics that have a positive correlation to my health.
Among the most important is VO₂ max, and personally, I’ve been putting in the work to optimize it.
If you’d like to learn more, you can read my newsletter below:

Another goal you might want to optimize for is financial security.
In the present, you might be focused on intense budgeting, spending huge amounts of time scouring the internet for coupons to accompany your purchases.
To be clear, I’m not saying this is an outright bad thing.
The point here is that your model is likely to teach you that spending your time increasing your income is much more important to achieving financial security.
At the end of the day, it’s all about figuring out what to prioritize.
Once you’ve got an initial idea of what you should be prioritizing, you can:
Start tracking even more data to further refine your model through iteration (just like a neural network would)
Create multiple models that will help you better implement behaviors that optimize your main model
Now you might be asking for clarification on my second bullet point.
Here’s what I mean:
You can create multiple models that all work together.
You’re simply changing what you’re optimizing for in each one.
For example, now that I know VO₂ max is important to optimizing my overall health, I can create an entirely separate model with the goal of improving my VO₂ max.
For my new model, I would identify the most important factors that influence VO₂ max.
Some of the inputs I analyze as a part of this model might be:
Resting Heart Rate
Time Spent in Exercise Zone 5
Maximal Heart Rate
Body Fat Percentage
Now let’s go a level deeper:
Let’s say I find out the amount of time spent training in Zone 5 has a high positive correlation to my VO2 max.
I can create another model that enables me to understand the most important factors when it comes to maximizing my time spent in Zone 5.
The inputs that would be a part of this model could be:
Anaerobic Threshold (Lactate Threshold)
Lactate Clearance Rate
Glycogen Stores
Hydration Status
You can get as granular as you want with this.
This approach allows you to not only iterate on your master model targeted at achieving your overall goal, but also iterate toward improving the individual actions that increase or decrease those metrics.
When you continue this process over a long enough period of time, you’re virtually guaranteed to reach your goals — even when you’re starting from scratch.
Malcolm Gladwell popularized the idea that it takes 10,000 hours of deliberate practice to become an expert in a field in his 2008 book Outliers: The Story of Success.
"Ten thousand hours is the magic number of greatness."
Gladwell nails it here.
By applying the principles of building neural network’s to your pursuits, you open the doors to limitless improvement (as fast as it can be done).
You’ve been given the only framework you need to reach your goals.
All thats left to do is execute.
Until next time.
— Landon